Starter Code
Project 1
Step 1: Load the data and perform basic operations.
1. Load the data in using pandas.
import numpy as np
import pandas as pd
sat = pd.read_csv('../data/sat.csv', index_col=0)
sat.head()
| State | Participation | Evidence-Based Reading and Writing | Math | Total | |
|---|---|---|---|---|---|
| 0 | Alabama | 5% | 593 | 572 | 1165 |
| 1 | Alaska | 38% | 547 | 533 | 1080 |
| 2 | Arizona | 30% | 563 | 553 | 1116 |
| 3 | Arkansas | 3% | 614 | 594 | 1208 |
| 4 | California | 53% | 531 | 524 | 1055 |
act = pd.read_csv('../data/act.csv', index_col=0)
act.head()
| State | Participation | English | Math | Reading | Science | Composite | |
|---|---|---|---|---|---|---|---|
| 0 | National | 60% | 20.3 | 20.7 | 21.4 | 21.0 | 21.0 |
| 1 | Alabama | 100% | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 |
| 2 | Alaska | 65% | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 |
| 3 | Arizona | 62% | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 |
| 4 | Arkansas | 100% | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 |
2. Print the first ten rows of each dataframe.
sat.head(10)
| State | Participation | Evidence-Based Reading and Writing | Math | Total | |
|---|---|---|---|---|---|
| 0 | Alabama | 5% | 593 | 572 | 1165 |
| 1 | Alaska | 38% | 547 | 533 | 1080 |
| 2 | Arizona | 30% | 563 | 553 | 1116 |
| 3 | Arkansas | 3% | 614 | 594 | 1208 |
| 4 | California | 53% | 531 | 524 | 1055 |
| 5 | Colorado | 11% | 606 | 595 | 1201 |
| 6 | Connecticut | 100% | 530 | 512 | 1041 |
| 7 | Delaware | 100% | 503 | 492 | 996 |
| 8 | District of Columbia | 100% | 482 | 468 | 950 |
| 9 | Florida | 83% | 520 | 497 | 1017 |
act.head(10)
| State | Participation | English | Math | Reading | Science | Composite | |
|---|---|---|---|---|---|---|---|
| 0 | National | 60% | 20.3 | 20.7 | 21.4 | 21.0 | 21.0 |
| 1 | Alabama | 100% | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 |
| 2 | Alaska | 65% | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 |
| 3 | Arizona | 62% | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 |
| 4 | Arkansas | 100% | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 |
| 5 | California | 31% | 22.5 | 22.7 | 23.1 | 22.2 | 22.8 |
| 6 | Colorado | 100% | 20.1 | 20.3 | 21.2 | 20.9 | 20.8 |
| 7 | Connecticut | 31% | 25.5 | 24.6 | 25.6 | 24.6 | 25.2 |
| 8 | Delaware | 18% | 24.1 | 23.4 | 24.8 | 23.6 | 24.1 |
| 9 | District of Columbia | 32% | 24.4 | 23.5 | 24.9 | 23.5 | 24.2 |
3. Describe in words what each variable (column) is.
SAT
- No column header. Looks to be the index.
- State: What state the row of data is for.
- Participation: Percent of HS seniors in that state took the test.
- Evidenced-Based Reading and Writing: Avg. (mean) score for that section of the test.
- Math: Avg. (mean) score for that section of the test.
- Total: Sum of two section scores
ACT
- No column header. Looks to be the index.
- State: What state the row of data is for.
- Participation: Percent of HS seniors in that state took the test.
- English: Avg. (mean) score for that section of the test.
- Math: Avg. (mean) score for that section of the test.
- Reading: Avg. (mean) score for that section of the test.
- Science: Avg. (mean) score for that section of the test.
- Composite: Avg. (mean) score for all sections.
4. Does the data look complete? Are there any obvious issues with the observations?
5. Print the types of each column.
sat.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 51 entries, 0 to 50
Data columns (total 5 columns):
State 51 non-null object
Participation 51 non-null object
Evidence-Based Reading and Writing 51 non-null int64
Math 51 non-null int64
Total 51 non-null int64
dtypes: int64(3), object(2)
memory usage: 2.4+ KB
act.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 52 entries, 0 to 51
Data columns (total 7 columns):
State 52 non-null object
Participation 52 non-null object
English 52 non-null float64
Math 52 non-null float64
Reading 52 non-null float64
Science 52 non-null float64
Composite 52 non-null float64
dtypes: float64(5), object(2)
memory usage: 3.2+ KB
6. Do any types need to be reassigned? If so, go ahead and do it.
- Participation data type for both sets is ‘object’ - will go ahead and change them to float.
# checking how to change object % to proper float value
a = sat['Participation'][0]
float(a.strip('%'))/100
0.05
sat['Participation'] = [float(i.strip('%'))/100 for i in sat['Participation']]
sat.head()
| State | Participation | Evidence-Based Reading and Writing | Math | Total | |
|---|---|---|---|---|---|
| 0 | Alabama | 0.05 | 593 | 572 | 1165 |
| 1 | Alaska | 0.38 | 547 | 533 | 1080 |
| 2 | Arizona | 0.30 | 563 | 553 | 1116 |
| 3 | Arkansas | 0.03 | 614 | 594 | 1208 |
| 4 | California | 0.53 | 531 | 524 | 1055 |
act['Participation'] = [float(i.strip('%'))/100 for i in act['Participation']]
act.head()
| State | Participation | English | Math | Reading | Science | Composite | |
|---|---|---|---|---|---|---|---|
| 0 | National | 0.60 | 20.3 | 20.7 | 21.4 | 21.0 | 21.0 |
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 |
| 3 | Arizona | 0.62 | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 |
| 4 | Arkansas | 1.00 | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 |
7. Create a dictionary for each column mapping the State to its respective value for that column. (For example, you should have three SAT dictionaries.)
# # [i for i in sat.columns[2:]]
# # messing around and trying to automate everything. unfortunately can't do that with new dict names
# for i in sat.columns[2:]:
# for j in range(len(sat)):
# pass
# #longer way
# sat_math = {}
# for i in range(len(sat)):
# d.update({sat['State'][i]:act['Composite'][i]})
# Creating ACT dictionaries, the better comprehension way
act_dict_english = {act['State'][i]:act['English'][i] for i in range(len(act))}
act_dict_math = {act['State'][i]:act['Math'][i] for i in range(len(act))}
act_dict_reading = {act['State'][i]:act['Reading'][i] for i in range(len(act))}
act_dict_science = {act['State'][i]:act['Science'][i] for i in range(len(act))}
act_dict_composite = {act['State'][i]:act['Composite'][i] for i in range(len(act))}
# Creating SAT dictionaries, the better comprehension way
sat_dict_ev_read_write = {sat['State'][i]:sat['Evidence-Based Reading and Writing'][i] for i in range(len(sat))}
sat_dict_math = {sat['State'][i]:sat['Math'][i] for i in range(len(sat))}
sat_dict_total = {sat['State'][i]:sat['Total'][i] for i in range(len(sat))}
8. Create one dictionary where each key is the column name, and each value is an iterable (a list or a Pandas Series) of all the values in that column.
col_dict = {i:sat[i].values for i in sat.columns}
col_dict
{'State': array(['Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California',
'Colorado', 'Connecticut', 'Delaware', 'District of Columbia',
'Florida', 'Georgia', 'Hawaii', 'Idaho', 'Illinois', 'Indiana',
'Iowa', 'Kansas', 'Kentucky', 'Louisiana', 'Maine', 'Maryland',
'Massachusetts', 'Michigan', 'Minnesota', 'Mississippi',
'Missouri', 'Montana', 'Nebraska', 'Nevada', 'New Hampshire',
'New Jersey', 'New Mexico', 'New York', 'North Carolina',
'North Dakota', 'Ohio', 'Oklahoma', 'Oregon', 'Pennsylvania',
'Rhode Island', 'South Carolina', 'South Dakota', 'Tennessee',
'Texas', 'Utah', 'Vermont', 'Virginia', 'Washington',
'West Virginia', 'Wisconsin', 'Wyoming'], dtype=object),
'Participation': array([0.05, 0.38, 0.3 , 0.03, 0.53, 0.11, 1. , 1. , 1. , 0.83, 0.61,
0.55, 0.93, 0.09, 0.63, 0.02, 0.04, 0.04, 0.04, 0.95, 0.69, 0.76,
1. , 0.03, 0.02, 0.03, 0.1 , 0.03, 0.26, 0.96, 0.7 , 0.11, 0.67,
0.49, 0.02, 0.12, 0.07, 0.43, 0.65, 0.71, 0.5 , 0.03, 0.05, 0.62,
0.03, 0.6 , 0.65, 0.64, 0.14, 0.03, 0.03]),
'Evidence-Based Reading and Writing': array([593, 547, 563, 614, 531, 606, 530, 503, 482, 520, 535, 544, 513,
559, 542, 641, 632, 631, 611, 513, 536, 555, 509, 644, 634, 640,
605, 629, 563, 532, 530, 577, 528, 546, 635, 578, 530, 560, 540,
539, 543, 612, 623, 513, 624, 562, 561, 541, 558, 642, 626],
dtype=int64),
'Math': array([572, 533, 553, 594, 524, 595, 512, 492, 468, 497, 515, 541, 493,
556, 532, 635, 628, 616, 586, 499, 52, 551, 495, 651, 607, 631,
591, 625, 553, 520, 526, 561, 523, 535, 621, 570, 517, 548, 531,
524, 521, 603, 604, 507, 614, 551, 541, 534, 528, 649, 604],
dtype=int64),
'Total': array([1165, 1080, 1116, 1208, 1055, 1201, 1041, 996, 950, 1017, 1050,
1085, 1005, 1115, 1074, 1275, 1260, 1247, 1198, 1012, 1060, 1107,
1005, 1295, 1242, 1271, 1196, 1253, 1116, 1052, 1056, 1138, 1052,
1081, 1256, 1149, 1047, 1108, 1071, 1062, 1064, 1216, 1228, 1020,
1238, 1114, 1102, 1075, 1086, 1291, 1230], dtype=int64)}
9. Merge the dataframes on the state column.
# both = pd.merge(sat, act, how='left',suffixes=('_sat','_act')) -- this did NOT work
# both = pd.concat([sat, act], axis=1, join_axes=[act.index], suffixes=('_sat','_act'))
both = pd.merge(act, sat, how='left', on='State', suffixes=('_act','_sat'))
both['State'].unique()
array(['National', 'Alabama', 'Alaska', 'Arizona', 'Arkansas',
'California', 'Colorado', 'Connecticut', 'Delaware',
'District of Columbia', 'Florida', 'Georgia', 'Hawaii', 'Idaho',
'Illinois', 'Indiana', 'Iowa', 'Kansas', 'Kentucky', 'Louisiana',
'Maine', 'Maryland', 'Massachusetts', 'Michigan', 'Minnesota',
'Mississippi', 'Missouri', 'Montana', 'Nebraska', 'Nevada',
'New Hampshire', 'New Jersey', 'New Mexico', 'New York',
'North Carolina', 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon',
'Pennsylvania', 'Rhode Island', 'South Carolina', 'South Dakota',
'Tennessee', 'Texas', 'Utah', 'Vermont', 'Virginia', 'Washington',
'West Virginia', 'Wisconsin', 'Wyoming'], dtype=object)
both.head()
| State | Participation_act | English | Math_act | Reading | Science | Composite | Participation_sat | Evidence-Based Reading and Writing | Math_sat | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | National | 0.60 | 20.3 | 20.7 | 21.4 | 21.0 | 21.0 | NaN | NaN | NaN | NaN |
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 |
| 3 | Arizona | 0.62 | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 | 0.30 | 563.0 | 553.0 | 1116.0 |
| 4 | Arkansas | 1.00 | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 | 0.03 | 614.0 | 594.0 | 1208.0 |
10. Change the names of the columns so you can distinguish between the SAT columns and the ACT columns.
#first, gonna make everything lower case
lower_names = []
for i in both.columns:
lower_names.append(i.lower())
both.columns = lower_names
###### SCRAP THIS VERSION ######
# #then, gonna change the ones we didn't already add a suffix to
# act_cols = ['english', 'reading', 'science', 'composite']
# sat_cols = ['evidence-based reading and writing', 'total']
# act_new_cols = [i+'_act' for i in act_cols]
# sat_new_cols = [i+'_sat' for i in sat_cols]
new_cols = ['state', 'participation_act', 'english_act', 'math_act','reading_act', 'science_act','composite_act',
'participation_sat','evidence-based reading and writing_sat', 'math_sat','total_sat']
both.columns = new_cols
both.head()
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | National | 0.60 | 20.3 | 20.7 | 21.4 | 21.0 | 21.0 | NaN | NaN | NaN | NaN |
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 |
| 3 | Arizona | 0.62 | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 | 0.30 | 563.0 | 553.0 | 1116.0 |
| 4 | Arkansas | 1.00 | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 | 0.03 | 614.0 | 594.0 | 1208.0 |
both['english_act'].max()
25.5
11. Print the minimum and maximum of each numeric column in the data frame.
# ###### OLD, SLOW WAY #####
# numeric_cols = ['english_act', 'math_sat', 'reading_act', 'science_act', 'composite_act',
# 'evidence-based reading and writing_sat', 'math_act', 'total_sat']
# for i in both.columns:
# if i in numeric_cols:
# print('Min and Max of {}: ({}, {})'.format(i, both[i].min(),both[i].max()))
# #### OLD WAY, WITHOUT PARTICIPATION ####
# numeric_cols = ['english_act', 'math_act', 'reading_act', 'science_act', 'composite_act',
# 'evidence-based reading and writing_sat', 'math_sat', 'total_sat']
# #### NEW WAY, incl. PARTICIPATION ####
numeric_cols = list(both.columns)[1:]
minmax = [(both[i].min(), both[i].max()) for i in both.columns if i in numeric_cols]
for i in range(len(numeric_cols)):
print('Min and Max of {}: {}'.format(numeric_cols[i], minmax[i]))
Min and Max of participation_act: (0.08, 1.0)
Min and Max of english_act: (16.3, 25.5)
Min and Max of math_act: (18.0, 25.3)
Min and Max of reading_act: (18.1, 26.0)
Min and Max of science_act: (2.3, 24.9)
Min and Max of composite_act: (17.8, 25.5)
Min and Max of participation_sat: (0.02, 1.0)
Min and Max of evidence-based reading and writing_sat: (482.0, 644.0)
Min and Max of math_sat: (52.0, 651.0)
Min and Max of total_sat: (950.0, 1295.0)
12. Write a function using only list comprehensions, no loops, to compute standard deviation. Using this function, calculate the standard deviation of each numeric column in both data sets. Add these to a list called sd.
def std_dev(sample):
"""Computes standard deviation using list comprehensions."""
std = np.sqrt(np.sum([((i - np.nanmean(sample))**2) for i in sample]) / len(sample))
return std
# check that it works!
print(std_dev(both[numeric_cols[0]]))
print(np.std(both[numeric_cols[0]]))
0.3152495020150073
0.3152495020150073
numeric_cols
['participation_act',
'english_act',
'math_act',
'reading_act',
'science_act',
'composite_act',
'participation_sat',
'evidence-based reading and writing_sat',
'math_sat',
'total_sat']
std_dev(both['evidence-based reading and writing_sat'])
nan
np.nanmean(both['math_sat'])
547.6274509803922
both.head()
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | National | 0.60 | 20.3 | 20.7 | 21.4 | 21.0 | 21.0 | NaN | NaN | NaN | NaN |
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 |
| 3 | Arizona | 0.62 | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 | 0.30 | 563.0 | 553.0 | 1116.0 |
| 4 | Arkansas | 1.00 | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 | 0.03 | 614.0 | 594.0 | 1208.0 |
both.loc[:,['evidence-based reading and writing_sat', 'math_sat', 'total_sat']].head()
| evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|
| 0 | NaN | NaN | NaN |
| 1 | 593.0 | 572.0 | 1165.0 |
| 2 | 547.0 | 533.0 | 1080.0 |
| 3 | 563.0 | 553.0 | 1116.0 |
| 4 | 614.0 | 594.0 | 1208.0 |
# dropping NaN national row
both.dropna(inplace=True)
both.head()
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 |
| 3 | Arizona | 0.62 | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 | 0.30 | 563.0 | 553.0 | 1116.0 |
| 4 | Arkansas | 1.00 | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 | 0.03 | 614.0 | 594.0 | 1208.0 |
| 5 | California | 0.31 | 22.5 | 22.7 | 23.1 | 22.2 | 22.8 | 0.53 | 531.0 | 524.0 | 1055.0 |
sd = [std_dev(both[i]) for i in numeric_cols]
print(sd,'\n', 'len is',len(sd))
[0.31824175751231804, 2.3304876369363368, 1.9624620273436781, 2.046902931484265, 3.151107895464408, 2.0007860815819893, 0.3492907076664507, 45.21697020437866, 84.07255521608297, 91.58351056778743]
len is 10
Step 2: Manipulate the dataframe
13. Turn the list sd into a new observation in your dataset.
# add a row label that would match up with 'state' to make the sd list the same length as the # of cols in dataframe
sd.insert(0, 'std_dev')
sd
['std_dev',
0.31824175751231804,
2.3304876369363368,
1.9624620273436781,
2.046902931484265,
3.151107895464408,
2.0007860815819893,
0.3492907076664507,
45.21697020437866,
84.07255521608297,
91.58351056778743]
both.index[-1]
51
# put it on the end row
both.loc[52] = sd
both.tail()
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 48 | Washington | 0.290000 | 20.900000 | 21.900000 | 22.100000 | 22.000000 | 21.900000 | 0.640000 | 541.00000 | 534.000000 | 1075.000000 |
| 49 | West Virginia | 0.690000 | 20.000000 | 19.400000 | 21.200000 | 20.500000 | 20.400000 | 0.140000 | 558.00000 | 528.000000 | 1086.000000 |
| 50 | Wisconsin | 1.000000 | 19.700000 | 20.400000 | 20.600000 | 20.900000 | 20.500000 | 0.030000 | 642.00000 | 649.000000 | 1291.000000 |
| 51 | Wyoming | 1.000000 | 19.400000 | 19.800000 | 20.800000 | 20.600000 | 20.200000 | 0.030000 | 626.00000 | 604.000000 | 1230.000000 |
| 52 | std_dev | 0.318242 | 2.330488 | 1.962462 | 2.046903 | 3.151108 | 2.000786 | 0.349291 | 45.21697 | 84.072555 | 91.583511 |
14. Sort the dataframe by the values in a numeric column (e.g. observations descending by SAT participation rate)
both.sort_values(by='total_sat', ascending=False)
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 24 | Minnesota | 1.000000 | 20.400000 | 21.500000 | 21.800000 | 21.600000 | 21.500000 | 0.030000 | 644.00000 | 651.000000 | 1295.000000 |
| 50 | Wisconsin | 1.000000 | 19.700000 | 20.400000 | 20.600000 | 20.900000 | 20.500000 | 0.030000 | 642.00000 | 649.000000 | 1291.000000 |
| 16 | Iowa | 0.670000 | 21.200000 | 21.300000 | 22.600000 | 22.100000 | 21.900000 | 0.020000 | 641.00000 | 635.000000 | 1275.000000 |
| 26 | Missouri | 1.000000 | 19.800000 | 19.900000 | 20.800000 | 20.500000 | 20.400000 | 0.030000 | 640.00000 | 631.000000 | 1271.000000 |
| 17 | Kansas | 0.730000 | 21.100000 | 21.300000 | 22.300000 | 21.700000 | 21.700000 | 0.040000 | 632.00000 | 628.000000 | 1260.000000 |
| 35 | North Dakota | 0.980000 | 19.000000 | 20.400000 | 20.500000 | 20.600000 | 20.300000 | 0.020000 | 635.00000 | 621.000000 | 1256.000000 |
| 28 | Nebraska | 0.840000 | 20.900000 | 20.900000 | 21.900000 | 21.500000 | 21.400000 | 0.030000 | 629.00000 | 625.000000 | 1253.000000 |
| 18 | Kentucky | 1.000000 | 19.600000 | 19.400000 | 20.500000 | 20.100000 | 20.000000 | 0.040000 | 631.00000 | 616.000000 | 1247.000000 |
| 25 | Mississippi | 1.000000 | 18.200000 | 18.100000 | 18.800000 | 18.800000 | 18.600000 | 0.020000 | 634.00000 | 607.000000 | 1242.000000 |
| 45 | Utah | 1.000000 | 19.500000 | 19.900000 | 20.800000 | 20.600000 | 20.300000 | 0.030000 | 624.00000 | 614.000000 | 1238.000000 |
| 51 | Wyoming | 1.000000 | 19.400000 | 19.800000 | 20.800000 | 20.600000 | 20.200000 | 0.030000 | 626.00000 | 604.000000 | 1230.000000 |
| 43 | Tennessee | 1.000000 | 19.500000 | 19.200000 | 20.100000 | 19.900000 | 19.800000 | 0.050000 | 623.00000 | 604.000000 | 1228.000000 |
| 42 | South Dakota | 0.800000 | 20.700000 | 21.500000 | 22.300000 | 22.000000 | 21.800000 | 0.030000 | 612.00000 | 603.000000 | 1216.000000 |
| 4 | Arkansas | 1.000000 | 18.900000 | 19.000000 | 19.700000 | 19.500000 | 19.400000 | 0.030000 | 614.00000 | 594.000000 | 1208.000000 |
| 6 | Colorado | 1.000000 | 20.100000 | 20.300000 | 21.200000 | 20.900000 | 20.800000 | 0.110000 | 606.00000 | 595.000000 | 1201.000000 |
| 19 | Louisiana | 1.000000 | 19.400000 | 18.800000 | 19.800000 | 19.600000 | 19.500000 | 0.040000 | 611.00000 | 586.000000 | 1198.000000 |
| 27 | Montana | 1.000000 | 19.000000 | 20.200000 | 21.000000 | 20.500000 | 20.300000 | 0.100000 | 605.00000 | 591.000000 | 1196.000000 |
| 1 | Alabama | 1.000000 | 18.900000 | 18.400000 | 19.700000 | 19.400000 | 19.200000 | 0.050000 | 593.00000 | 572.000000 | 1165.000000 |
| 36 | Ohio | 0.750000 | 21.200000 | 21.600000 | 22.500000 | 22.000000 | 22.000000 | 0.120000 | 578.00000 | 570.000000 | 1149.000000 |
| 32 | New Mexico | 0.660000 | 18.600000 | 19.400000 | 20.400000 | 20.000000 | 19.700000 | 0.110000 | 577.00000 | 561.000000 | 1138.000000 |
| 3 | Arizona | 0.620000 | 18.600000 | 19.800000 | 20.100000 | 19.800000 | 19.700000 | 0.300000 | 563.00000 | 553.000000 | 1116.000000 |
| 29 | Nevada | 1.000000 | 16.300000 | 18.000000 | 18.100000 | 18.200000 | 17.800000 | 0.260000 | 563.00000 | 553.000000 | 1116.000000 |
| 14 | Illinois | 0.930000 | 21.000000 | 21.200000 | 21.600000 | 21.300000 | 21.400000 | 0.090000 | 559.00000 | 556.000000 | 1115.000000 |
| 46 | Vermont | 0.290000 | 23.300000 | 23.100000 | 24.400000 | 23.200000 | 23.600000 | 0.600000 | 562.00000 | 551.000000 | 1114.000000 |
| 38 | Oregon | 0.400000 | 21.200000 | 21.500000 | 22.400000 | 21.700000 | 21.800000 | 0.430000 | 560.00000 | 548.000000 | 1108.000000 |
| 22 | Massachusetts | 0.290000 | 25.400000 | 25.300000 | 25.900000 | 24.700000 | 25.400000 | 0.760000 | 555.00000 | 551.000000 | 1107.000000 |
| 47 | Virginia | 0.290000 | 23.500000 | 23.300000 | 24.600000 | 23.500000 | 23.800000 | 0.650000 | 561.00000 | 541.000000 | 1102.000000 |
| 49 | West Virginia | 0.690000 | 20.000000 | 19.400000 | 21.200000 | 20.500000 | 20.400000 | 0.140000 | 558.00000 | 528.000000 | 1086.000000 |
| 12 | Hawaii | 0.900000 | 17.800000 | 19.200000 | 19.200000 | 19.300000 | 19.000000 | 0.550000 | 544.00000 | 541.000000 | 1085.000000 |
| 34 | North Carolina | 1.000000 | 17.800000 | 19.300000 | 19.600000 | 19.300000 | 19.100000 | 0.490000 | 546.00000 | 535.000000 | 1081.000000 |
| 2 | Alaska | 0.650000 | 18.700000 | 19.800000 | 20.400000 | 19.900000 | 19.800000 | 0.380000 | 547.00000 | 533.000000 | 1080.000000 |
| 48 | Washington | 0.290000 | 20.900000 | 21.900000 | 22.100000 | 22.000000 | 21.900000 | 0.640000 | 541.00000 | 534.000000 | 1075.000000 |
| 15 | Indiana | 0.350000 | 22.000000 | 22.400000 | 23.200000 | 22.300000 | 22.600000 | 0.630000 | 542.00000 | 532.000000 | 1074.000000 |
| 39 | Pennsylvania | 0.230000 | 23.400000 | 23.400000 | 24.200000 | 23.300000 | 23.700000 | 0.650000 | 540.00000 | 531.000000 | 1071.000000 |
| 41 | South Carolina | 1.000000 | 17.500000 | 18.600000 | 19.100000 | 18.900000 | 18.700000 | 0.500000 | 543.00000 | 521.000000 | 1064.000000 |
| 40 | Rhode Island | 0.210000 | 24.000000 | 23.300000 | 24.700000 | 23.400000 | 24.000000 | 0.710000 | 539.00000 | 524.000000 | 1062.000000 |
| 21 | Maryland | 0.280000 | 23.300000 | 23.100000 | 24.200000 | 2.300000 | 23.600000 | 0.690000 | 536.00000 | 52.000000 | 1060.000000 |
| 31 | New Jersey | 0.340000 | 23.800000 | 23.800000 | 24.100000 | 23.200000 | 23.900000 | 0.700000 | 530.00000 | 526.000000 | 1056.000000 |
| 5 | California | 0.310000 | 22.500000 | 22.700000 | 23.100000 | 22.200000 | 22.800000 | 0.530000 | 531.00000 | 524.000000 | 1055.000000 |
| 33 | New York | 0.310000 | 23.800000 | 24.000000 | 24.600000 | 23.900000 | 24.200000 | 0.670000 | 528.00000 | 523.000000 | 1052.000000 |
| 30 | New Hampshire | 0.180000 | 25.400000 | 25.100000 | 26.000000 | 24.900000 | 25.500000 | 0.960000 | 532.00000 | 520.000000 | 1052.000000 |
| 11 | Georgia | 0.550000 | 21.000000 | 20.900000 | 22.000000 | 21.300000 | 21.400000 | 0.610000 | 535.00000 | 515.000000 | 1050.000000 |
| 37 | Oklahoma | 1.000000 | 18.500000 | 18.800000 | 20.100000 | 19.600000 | 19.400000 | 0.070000 | 530.00000 | 517.000000 | 1047.000000 |
| 7 | Connecticut | 0.310000 | 25.500000 | 24.600000 | 25.600000 | 24.600000 | 25.200000 | 1.000000 | 530.00000 | 512.000000 | 1041.000000 |
| 44 | Texas | 0.450000 | 19.500000 | 20.700000 | 21.100000 | 20.900000 | 20.700000 | 0.620000 | 513.00000 | 507.000000 | 1020.000000 |
| 10 | Florida | 0.730000 | 19.000000 | 19.400000 | 21.000000 | 19.400000 | 19.800000 | 0.830000 | 520.00000 | 497.000000 | 1017.000000 |
| 20 | Maine | 0.080000 | 24.200000 | 24.000000 | 24.800000 | 23.700000 | 24.300000 | 0.950000 | 513.00000 | 499.000000 | 1012.000000 |
| 13 | Idaho | 0.380000 | 21.900000 | 21.800000 | 23.000000 | 22.100000 | 22.300000 | 0.930000 | 513.00000 | 493.000000 | 1005.000000 |
| 23 | Michigan | 0.290000 | 24.100000 | 23.700000 | 24.500000 | 23.800000 | 24.100000 | 1.000000 | 509.00000 | 495.000000 | 1005.000000 |
| 8 | Delaware | 0.180000 | 24.100000 | 23.400000 | 24.800000 | 23.600000 | 24.100000 | 1.000000 | 503.00000 | 492.000000 | 996.000000 |
| 9 | District of Columbia | 0.320000 | 24.400000 | 23.500000 | 24.900000 | 23.500000 | 24.200000 | 1.000000 | 482.00000 | 468.000000 | 950.000000 |
| 52 | std_dev | 0.318242 | 2.330488 | 1.962462 | 2.046903 | 3.151108 | 2.000786 | 0.349291 | 45.21697 | 84.072555 | 91.583511 |
15. Use a boolean filter to display only observations with a score above a certain threshold (e.g. only states with a participation rate above 50%)
both[both['math_sat'] >= 600]
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | Iowa | 0.67 | 21.2 | 21.3 | 22.6 | 22.1 | 21.9 | 0.02 | 641.0 | 635.0 | 1275.0 |
| 17 | Kansas | 0.73 | 21.1 | 21.3 | 22.3 | 21.7 | 21.7 | 0.04 | 632.0 | 628.0 | 1260.0 |
| 18 | Kentucky | 1.00 | 19.6 | 19.4 | 20.5 | 20.1 | 20.0 | 0.04 | 631.0 | 616.0 | 1247.0 |
| 24 | Minnesota | 1.00 | 20.4 | 21.5 | 21.8 | 21.6 | 21.5 | 0.03 | 644.0 | 651.0 | 1295.0 |
| 25 | Mississippi | 1.00 | 18.2 | 18.1 | 18.8 | 18.8 | 18.6 | 0.02 | 634.0 | 607.0 | 1242.0 |
| 26 | Missouri | 1.00 | 19.8 | 19.9 | 20.8 | 20.5 | 20.4 | 0.03 | 640.0 | 631.0 | 1271.0 |
| 28 | Nebraska | 0.84 | 20.9 | 20.9 | 21.9 | 21.5 | 21.4 | 0.03 | 629.0 | 625.0 | 1253.0 |
| 35 | North Dakota | 0.98 | 19.0 | 20.4 | 20.5 | 20.6 | 20.3 | 0.02 | 635.0 | 621.0 | 1256.0 |
| 42 | South Dakota | 0.80 | 20.7 | 21.5 | 22.3 | 22.0 | 21.8 | 0.03 | 612.0 | 603.0 | 1216.0 |
| 43 | Tennessee | 1.00 | 19.5 | 19.2 | 20.1 | 19.9 | 19.8 | 0.05 | 623.0 | 604.0 | 1228.0 |
| 45 | Utah | 1.00 | 19.5 | 19.9 | 20.8 | 20.6 | 20.3 | 0.03 | 624.0 | 614.0 | 1238.0 |
| 50 | Wisconsin | 1.00 | 19.7 | 20.4 | 20.6 | 20.9 | 20.5 | 0.03 | 642.0 | 649.0 | 1291.0 |
| 51 | Wyoming | 1.00 | 19.4 | 19.8 | 20.8 | 20.6 | 20.2 | 0.03 | 626.0 | 604.0 | 1230.0 |
Step 3: Visualize the data
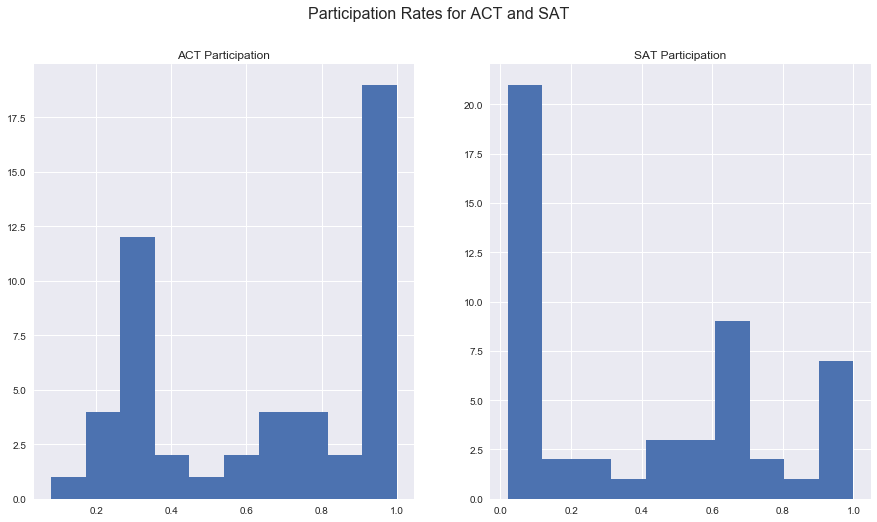
16. Using MatPlotLib and PyPlot, plot the distribution of the Rate columns for both SAT and ACT using histograms. (You should have two histograms. You might find this link helpful in organizing one plot above the other.)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
fig, ax = plt.subplots(1,2, figsize=(15,8))
fig.suptitle('Participation Rates for ACT and SAT', fontsize=16)
ax[0].hist(both[both['state'] != 'std_dev'].loc[:,'participation_act']);
ax[0].set(title='ACT Participation');
ax[1].hist(both[both['state'] != 'std_dev'].loc[:,'participation_sat']);
ax[1].set(title='SAT Participation');
# sat
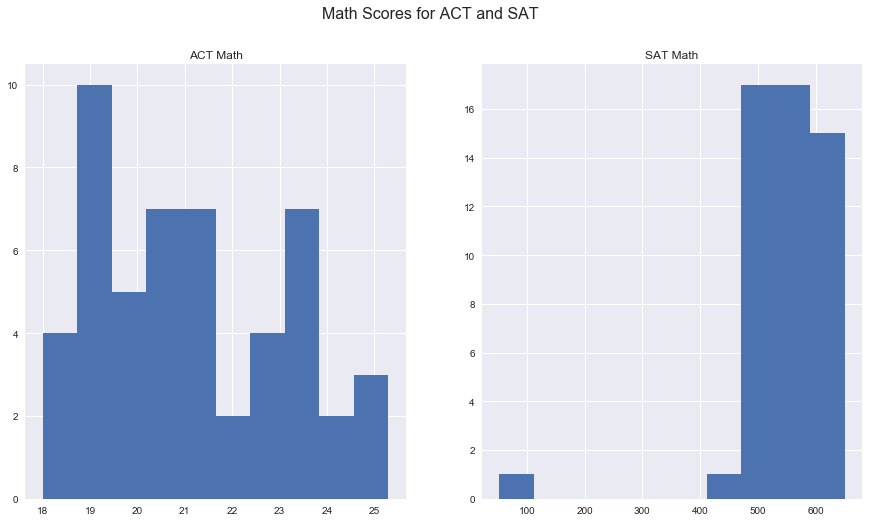
17. Plot the Math(s) distributions from both data sets.
fig, ax = plt.subplots(1,2, figsize=(15,8))
fig.suptitle('Math Scores for ACT and SAT', fontsize=16)
ax[0].hist(both[both['state'] != 'std_dev'].loc[:,'math_act']);
ax[0].set(title='ACT Math');
ax[1].hist(both[both['state'] != 'std_dev'].loc[:,'math_sat']);
ax[1].set(title='SAT Math');
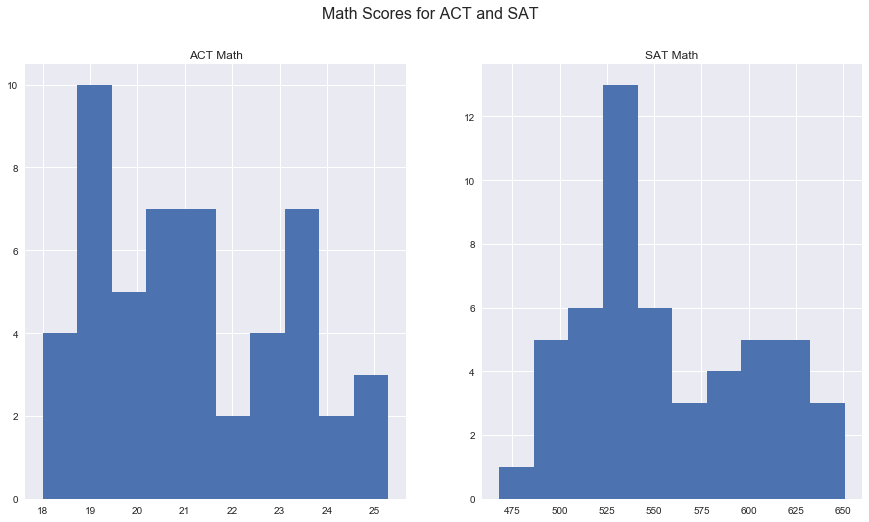
tests = both.copy()
tests.loc[21, 'math_sat'] = float(tests.loc[21, 'total_sat'] - tests.loc[21, 'evidence-based reading and writing_sat'])
tests.loc[18:24]
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 18 | Kentucky | 1.00 | 19.6 | 19.4 | 20.5 | 20.1 | 20.0 | 0.04 | 631.0 | 616.0 | 1247.0 |
| 19 | Louisiana | 1.00 | 19.4 | 18.8 | 19.8 | 19.6 | 19.5 | 0.04 | 611.0 | 586.0 | 1198.0 |
| 20 | Maine | 0.08 | 24.2 | 24.0 | 24.8 | 23.7 | 24.3 | 0.95 | 513.0 | 499.0 | 1012.0 |
| 21 | Maryland | 0.28 | 23.3 | 23.1 | 24.2 | 2.3 | 23.6 | 0.69 | 536.0 | 524.0 | 1060.0 |
| 22 | Massachusetts | 0.29 | 25.4 | 25.3 | 25.9 | 24.7 | 25.4 | 0.76 | 555.0 | 551.0 | 1107.0 |
| 23 | Michigan | 0.29 | 24.1 | 23.7 | 24.5 | 23.8 | 24.1 | 1.00 | 509.0 | 495.0 | 1005.0 |
| 24 | Minnesota | 1.00 | 20.4 | 21.5 | 21.8 | 21.6 | 21.5 | 0.03 | 644.0 | 651.0 | 1295.0 |
fig, ax = plt.subplots(1,2, figsize=(15,8))
fig.suptitle('Math Scores for ACT and SAT', fontsize=16)
ax[0].hist(tests[tests['state'] != 'std_dev'].loc[:,'math_act']);
ax[0].set(title='ACT Math');
ax[1].hist(tests[tests['state'] != 'std_dev'].loc[:,'math_sat']);
ax[1].set(title='SAT Math');
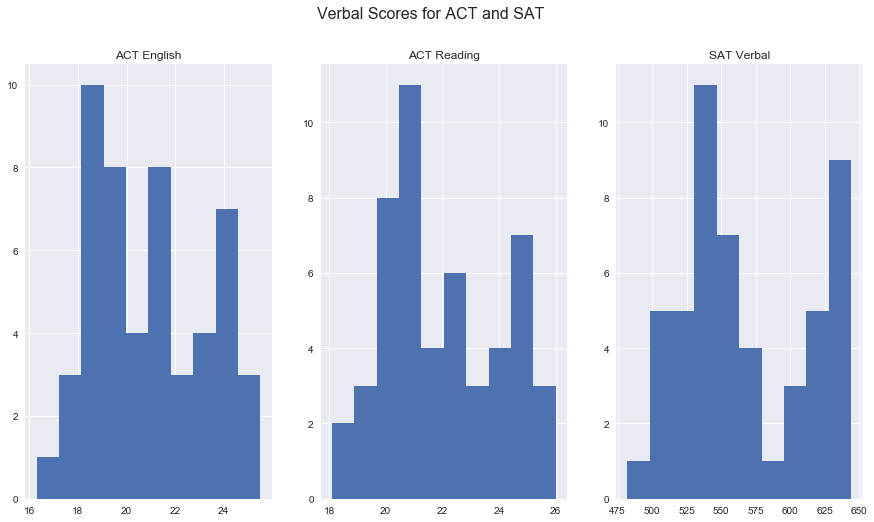
18. Plot the Verbal distributions from both data sets.
tests.head(2)
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 |
fig, ax = plt.subplots(1,3, figsize=(15,8))
fig.suptitle('Verbal Scores for ACT and SAT', fontsize=16)
ax[0].hist(tests[tests['state'] != 'std_dev'].loc[:,'english_act']);
ax[0].set(title='ACT English');
ax[1].hist(tests[tests['state'] != 'std_dev'].loc[:,'reading_act']);
ax[1].set(title='ACT Reading');
ax[2].hist(tests[tests['state'] != 'std_dev'].loc[:,'evidence-based reading and writing_sat']);
ax[2].set(title='SAT Verbal');
Adding in z-score columns
Here’s what I’m trying to do:
- Iteratively make new columns with ‘_zscore’ append to each numeric column (probably a for loop)
- For each of those columns, iterate over each state row and calculate z-score, then put it in (probably .apply(lambda x: x- [whichever is appr. mean])
- Then I can use those values as color scales for visualization (in Tableau, or learn with Seaborn or Pyplot)
# tests['math_sat']
dftestlist = [float(tests[tests['state'] == 'std_dev'][i].values) for i in list(tests.columns)[1:]]
zscorenames = [i+'_zscore' for i in list(tests.columns)[1:]]
zscorenames
['participation_act_zscore',
'english_act_zscore',
'math_act_zscore',
'reading_act_zscore',
'science_act_zscore',
'composite_act_zscore',
'participation_sat_zscore',
'evidence-based reading and writing_sat_zscore',
'math_sat_zscore',
'total_sat_zscore']
## use .map() or .apply()
df = pd.DataFrame(np.random.randint(low=0, high=10, size=(5, 5)),columns=['a', 'b', 'c', 'd', 'e'])
for i in tests.columns[1:]:
for j in zscorenames:
df[j] = tests[i].mean()
tests['math_act'].mean()
20.812739654371992
df[[i+'_zscore' for i in list(tests.columns)[1:]][0]] = np.random.randint(1,10)
df['participation_act_zscore'] = df['participation_act_zscore'].apply(lambda x: x - dftestlist[df.columns.get_loc('participation_act_zscore')])
df.head()
| a | b | c | d | e | participation_act_zscore | english_act_zscore | math_act_zscore | reading_act_zscore | science_act_zscore | composite_act_zscore | participation_sat_zscore | evidence-based reading and writing_sat_zscore | math_sat_zscore | total_sat_zscore | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 6 | 5 | 2 | 2 | 0.999214 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 |
| 1 | 1 | 5 | 4 | 8 | 3 | 0.999214 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 |
| 2 | 0 | 8 | 0 | 6 | 7 | 0.999214 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 |
| 3 | 1 | 3 | 9 | 9 | 4 | 0.999214 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 |
| 4 | 7 | 0 | 5 | 6 | 0 | 0.999214 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 | 1106.203529 |
19. When we make assumptions about how data are distributed, what is the most common assumption?
A: Generally we tend to assume it’s normally distributed, if anything
20. Does this assumption hold true for any of our columns? Which?
for i in range(len(tests.columns[1:])):
print(tests.columns[i+1])
participation_act
english_act
math_act
reading_act
science_act
composite_act
participation_sat
evidence-based reading and writing_sat
math_sat
total_sat
tests['science_act'][21] = 23.0
C:\Users\james\Anaconda3\envs\dsi\lib\site-packages\ipykernel\__main__.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
if __name__ == '__main__':
fig, ax = plt.subplots(nrows=len(tests.columns[1:]), ncols=1, figsize=(10, 40));
for i in range(len(tests.columns[1:])):
sns.distplot(
tests[tests['state'] != 'std_dev'].loc[:,tests.columns[i+1]],
ax=ax[i],
kde=True);
# ax[i].set_ylabel(tests.columns[i+1]);
C:\Users\james\Anaconda3\envs\dsi\lib\site-packages\matplotlib\axes\_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
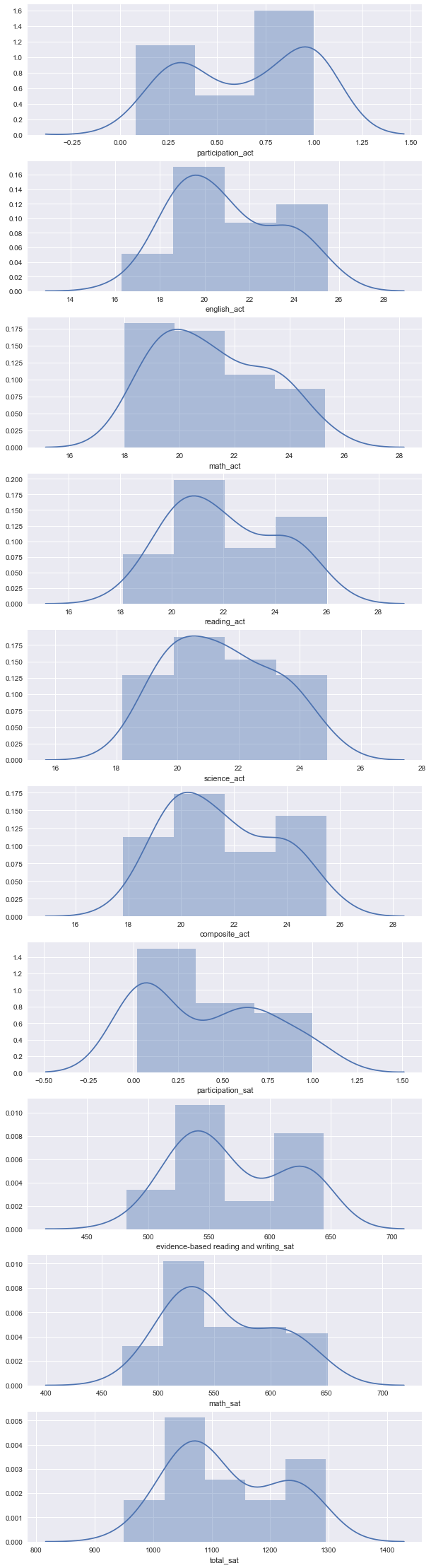
A: If anything, Science ACT scores are closes, but most look multi-modal or very skewed
21. Plot some scatterplots examining relationships between all variables.
# making some things easy on myself by dropping 'std_dev' row
new = tests.drop(52, axis=0)
new.tail(3)
| state | participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 49 | West Virginia | 0.69 | 20.0 | 19.4 | 21.2 | 20.5 | 20.4 | 0.14 | 558.0 | 528.0 | 1086.0 |
| 50 | Wisconsin | 1.00 | 19.7 | 20.4 | 20.6 | 20.9 | 20.5 | 0.03 | 642.0 | 649.0 | 1291.0 |
| 51 | Wyoming | 1.00 | 19.4 | 19.8 | 20.8 | 20.6 | 20.2 | 0.03 | 626.0 | 604.0 | 1230.0 |
sns.heatmap(new.corr());
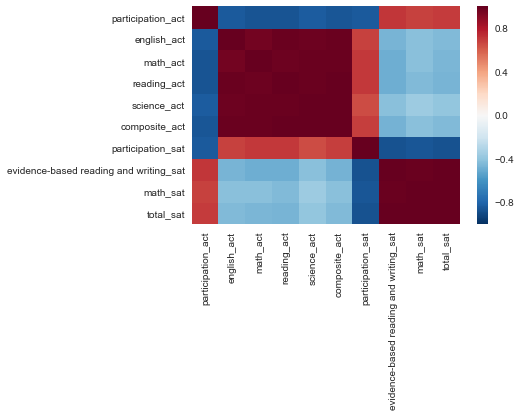
sns.heatmap(abs(new.corr()));

sns.pairplot(new);

22. Are there any interesting relationships to note?
A: ACT participation and SAT scores are negatively correlated (as well as the converse). This is likely because test-taksrs for those in states where one test has much higher participation than the other means that only ambitious, prepared students are taking the non-default test in their state.
23. Create box plots for each variable.
fig, ax = plt.subplots(nrows=len(new.columns[1:]), ncols=1, figsize=(10,40));
for i in range(len(new.columns[1:])):
sns.boxplot(new[new.columns[i+1]],
notch=False,
ax=ax[i]);
C:\Users\james\Anaconda3\envs\dsi\lib\site-packages\seaborn\categorical.py:454: FutureWarning: remove_na is deprecated and is a private function. Do not use.
box_data = remove_na(group_data)
BONUS: Using Tableau, create a heat map for each variable using a map of the US.
new.to_csv('../data/merged_test_data.csv')
Tableau dashboard here!: https://public.tableau.com/profile/jamiequella#!/vizhome/SAT_ACT/Dashboard1
Step 4: Descriptive and Inferential Statistics
24. Summarize each distribution. As data scientists, be sure to back up these summaries with statistics. (Hint: What are the three things we care about when describing distributions?)
#center, shape, spread. Center and Spread are below for each distribution
new.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| participation_act | 51.0 | 0.652549 | 0.321408 | 0.08 | 0.31 | 0.69 | 1.00 | 1.0 |
| english_act | 51.0 | 20.931373 | 2.353677 | 16.30 | 19.00 | 20.70 | 23.30 | 25.5 |
| math_act | 51.0 | 21.182353 | 1.981989 | 18.00 | 19.40 | 20.90 | 23.10 | 25.3 |
| reading_act | 51.0 | 22.013725 | 2.067271 | 18.10 | 20.45 | 21.80 | 24.15 | 26.0 |
| science_act | 51.0 | 21.447059 | 1.735552 | 18.20 | 19.95 | 21.30 | 23.10 | 24.9 |
| composite_act | 51.0 | 21.519608 | 2.020695 | 17.80 | 19.80 | 21.40 | 23.60 | 25.5 |
| participation_sat | 51.0 | 0.398039 | 0.352766 | 0.02 | 0.04 | 0.38 | 0.66 | 1.0 |
| evidence-based reading and writing_sat | 51.0 | 569.117647 | 45.666901 | 482.00 | 533.50 | 559.00 | 613.00 | 644.0 |
| math_sat | 51.0 | 556.882353 | 47.121395 | 468.00 | 523.50 | 548.00 | 599.00 | 651.0 |
| total_sat | 51.0 | 1126.098039 | 92.494812 | 950.00 | 1055.50 | 1107.00 | 1212.00 | 1295.0 |
# Shapes are below:
fig, ax = plt.subplots(nrows=len(tests.columns[1:]), ncols=1, figsize=(10, 40));
for i in range(len(tests.columns[1:])):
sns.distplot(
tests[tests['state'] != 'std_dev'].loc[:,tests.columns[i+1]],
ax=ax[i],
kde=True);
C:\Users\james\Anaconda3\envs\dsi\lib\site-packages\matplotlib\axes\_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "

25. Summarize each relationship. Be sure to back up these summaries with statistics.
A: See #21. Summary stats below.
new.corr()
| participation_act | english_act | math_act | reading_act | science_act | composite_act | participation_sat | evidence-based reading and writing_sat | math_sat | total_sat | |
|---|---|---|---|---|---|---|---|---|---|---|
| participation_act | 1.000000 | -0.843501 | -0.861114 | -0.866620 | -0.835756 | -0.858134 | -0.841234 | 0.716153 | 0.682572 | 0.701477 |
| english_act | -0.843501 | 1.000000 | 0.967803 | 0.985999 | 0.979869 | 0.990856 | 0.686889 | -0.461345 | -0.420673 | -0.441947 |
| math_act | -0.861114 | 0.967803 | 1.000000 | 0.979630 | 0.986860 | 0.990451 | 0.710697 | -0.486126 | -0.420456 | -0.454116 |
| reading_act | -0.866620 | 0.985999 | 0.979630 | 1.000000 | 0.987760 | 0.995069 | 0.705352 | -0.488441 | -0.442410 | -0.466558 |
| science_act | -0.835756 | 0.979869 | 0.986860 | 0.987760 | 1.000000 | 0.994935 | 0.653194 | -0.421383 | -0.364707 | -0.393776 |
| composite_act | -0.858134 | 0.990856 | 0.990451 | 0.995069 | 0.994935 | 1.000000 | 0.694748 | -0.470382 | -0.417817 | -0.445020 |
| participation_sat | -0.841234 | 0.686889 | 0.710697 | 0.705352 | 0.653194 | 0.694748 | 1.000000 | -0.874326 | -0.855091 | -0.867540 |
| evidence-based reading and writing_sat | 0.716153 | -0.461345 | -0.486126 | -0.488441 | -0.421383 | -0.470382 | -0.874326 | 1.000000 | 0.987056 | 0.996661 |
| math_sat | 0.682572 | -0.420673 | -0.420456 | -0.442410 | -0.364707 | -0.417817 | -0.855091 | 0.987056 | 1.000000 | 0.996822 |
| total_sat | 0.701477 | -0.441947 | -0.454116 | -0.466558 | -0.393776 | -0.445020 | -0.867540 | 0.996661 | 0.996822 | 1.000000 |
26. Execute a hypothesis test comparing the SAT and ACT participation rates. Use $\alpha = 0.05$. Be sure to interpret your results.
import scipy.stats as stats
new[['participation_act','participation_sat']].describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| participation_act | 51.0 | 0.652549 | 0.321408 | 0.08 | 0.31 | 0.69 | 1.00 | 1.0 |
| participation_sat | 51.0 | 0.398039 | 0.352766 | 0.02 | 0.04 | 0.38 | 0.66 | 1.0 |
# def sampler(population, n=30, k=1000):
# sample_means = []
# for i in range(k):
# sample = np.random.choice(population, size=n, replace=True)
# sample_means.append(np.mean(sample))
# return sample_means
Hypothesis Testing: Participation Rates
- Construct null hypothesis (and alternative).
- H0: The ACT participation rate is the same as SAT participation rate (difference in part. rates = 0)
- H1: ACT_partic != SAT_partic (dif in part. rates != 0)
- Specify a level of significance.
- $\alpha = 0.05$
. 3. Calculate your point estimate
experimental = new['participation_sat']
control = new['participation_act']
. 4. Calculate your test statistic
stats.ttest_ind(experimental, control)
Ttest_indResult(statistic=-3.8085778908170544, pvalue=0.00024134203698662353)
. 5. Find your p-value and make a conclusion
alpha = 0.05
p_hyp = stats.ttest_ind(experimental, control)[1]
p_hyp < alpha
True
Since p < $\alpha$, we have evidence to reject H0.
That is, the difference in participation rates between ACT and SAT across states is not 0, and not due to chance
27. Generate and interpret 95% confidence intervals for SAT and ACT participation rates.
def confidencer(sample, sd=0.95):
"""Take in sample and sig. level, then return CI
sample = dataset
sd = significance level, default 95%."""
zscore = stats.norm.ppf(1-(1-sd)/2)
low_ci = sample.mean() - zscore*sample.sem()
high_ci = sample.mean() + zscore*sample.sem()
# interval = (low_ci, high_ci)
# print((low_ci, high_ci))
# print("{0:.0f}% of similar sample means will fall between the range above.".format(sd*100))
return (low_ci, high_ci)
confidencer(new['participation_act'])
(0.5643385258470263, 0.7407595133686601)
confidencer(new['participation_sat'], .95)
(0.3012225501733267, 0.49485588119922247)
28. Given your answer to 26, was your answer to 27 surprising? Why?
A: No, because knowing that the part. rates are significantly different, I would expect them to have different ranges for the sample means we’re getting the 95% confidence intervals for
29. Is it appropriate to generate correlation between SAT and ACT math scores? Why?
A: It depends. There are many factors that go into how these avg. state scores came out: educational policies, funding, participation rates (perhaps we can weight correlations by that?), among others. Correlations are fine to look at in general since they are similarly-goaled aptitude tests. However, we should be careful about drawing any major conclusions from just the correlational data we have here.
30. Suppose we only seek to understand the relationship between SAT and ACT data in 2017. Does it make sense to conduct statistical inference given the data we have? Why?
A: Yes, because this data comes from that year. From the README:
These data give average SAT and ACT scores by state, as well as participation rates, for the graduating class of 2017.
EDA FOR PRESENTATION
** IGNORE EVERYTHING BELOW HERE FOR NOTEBOOK SCORING **
Some questions for myself to explore:
- What states have highest participation rates for ACT? SAT?
- What can we infer about them?
- What can we learn from states that have high part. rates of both? Low rates of both?
- What states have the highest deltas btwn SAT and ACT part. rate?
- Anything else we can learn from these?
- Do we know which states have mandatory testing for either SAT / ACT?
Some final questions to explore as takeaways for the ‘client’ group:
- Do we have any data in regards to college acceptance rates by state that we can correlate to SAT/ACT participation?
- Any median income or other data (5 yrs out) for those who took one test or another?
- Any data on colleges accepting SAT vs. ACT? Common app, etc?
- Is there any benefit to taking both tests?
- if not, do you want to throw eggs more into one basket vs. another?
eda = new.copy()
eda = eda.rename(columns={
'participation_act':'act_participation',
'english_act':'act_eng',
'math_act':'act_math',
'reading_act':'act_reading',
'science_act':'act_sci',
'composite_act':'act_composite',
'participation_sat':'sat_participation',
'evidence-based reading and writing_sat':'sat_erbw',
'math_sat':'sat_math',
'total_sat':'sat_total'
})
eda.head(2)
| state | act_participation | act_eng | act_math | act_reading | act_sci | act_composite | sat_participation | sat_erbw | sat_math | sat_total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 |
eda[['state','act_participation','sat_participation']].sort_values(by='act_participation', ascending=False)
| state | act_participation | sat_participation | |
|---|---|---|---|
| 1 | Alabama | 1.00 | 0.05 |
| 18 | Kentucky | 1.00 | 0.04 |
| 50 | Wisconsin | 1.00 | 0.03 |
| 45 | Utah | 1.00 | 0.03 |
| 43 | Tennessee | 1.00 | 0.05 |
| 41 | South Carolina | 1.00 | 0.50 |
| 37 | Oklahoma | 1.00 | 0.07 |
| 34 | North Carolina | 1.00 | 0.49 |
| 29 | Nevada | 1.00 | 0.26 |
| 27 | Montana | 1.00 | 0.10 |
| 25 | Mississippi | 1.00 | 0.02 |
| 24 | Minnesota | 1.00 | 0.03 |
| 19 | Louisiana | 1.00 | 0.04 |
| 26 | Missouri | 1.00 | 0.03 |
| 51 | Wyoming | 1.00 | 0.03 |
| 6 | Colorado | 1.00 | 0.11 |
| 4 | Arkansas | 1.00 | 0.03 |
| 35 | North Dakota | 0.98 | 0.02 |
| 14 | Illinois | 0.93 | 0.09 |
| 12 | Hawaii | 0.90 | 0.55 |
| 28 | Nebraska | 0.84 | 0.03 |
| 42 | South Dakota | 0.80 | 0.03 |
| 36 | Ohio | 0.75 | 0.12 |
| 10 | Florida | 0.73 | 0.83 |
| 17 | Kansas | 0.73 | 0.04 |
| 49 | West Virginia | 0.69 | 0.14 |
| 16 | Iowa | 0.67 | 0.02 |
| 32 | New Mexico | 0.66 | 0.11 |
| 2 | Alaska | 0.65 | 0.38 |
| 3 | Arizona | 0.62 | 0.30 |
| 11 | Georgia | 0.55 | 0.61 |
| 44 | Texas | 0.45 | 0.62 |
| 38 | Oregon | 0.40 | 0.43 |
| 13 | Idaho | 0.38 | 0.93 |
| 15 | Indiana | 0.35 | 0.63 |
| 31 | New Jersey | 0.34 | 0.70 |
| 9 | District of Columbia | 0.32 | 1.00 |
| 7 | Connecticut | 0.31 | 1.00 |
| 5 | California | 0.31 | 0.53 |
| 33 | New York | 0.31 | 0.67 |
| 23 | Michigan | 0.29 | 1.00 |
| 22 | Massachusetts | 0.29 | 0.76 |
| 46 | Vermont | 0.29 | 0.60 |
| 47 | Virginia | 0.29 | 0.65 |
| 48 | Washington | 0.29 | 0.64 |
| 21 | Maryland | 0.28 | 0.69 |
| 39 | Pennsylvania | 0.23 | 0.65 |
| 40 | Rhode Island | 0.21 | 0.71 |
| 8 | Delaware | 0.18 | 1.00 |
| 30 | New Hampshire | 0.18 | 0.96 |
| 20 | Maine | 0.08 | 0.95 |
# creating a column that measures difference in ACT and SAT participation
eda['particip_dif_act_sat'] = eda['act_participation'] - eda['sat_participation']
fig, ax = plt.subplots(figsize=(15,10));
ax = plt.gca();
eda['particip_dif_act_sat'].sort_values().plot(kind='barh', color='mediumorchid');
ax.set_yticklabels([i for i in eda['state'][eda['particip_dif_act_sat'].sort_values().index]]);

Creating a regional map for states to dig into the data a little deeper…
From here: https://en.wikipedia.org/wiki/List_of_regions_of_the_United_States#Interstate_regions
# dict for state -> region
region_map = {'Connecticut': 'Northeast', 'Maine': 'Northeast', 'Massachusetts': 'Northeast',
'New Hampshire': 'Northeast', 'Rhode Island': 'Northeast', 'Vermont': 'Northeast',
'New Jersey': 'Northeast', 'New York': 'Northeast', 'Pennsylvania': 'Northeast',
'Illinois': 'Midwest', 'Indiana': 'Midwest', 'Michigan': 'Midwest', 'Ohio': 'Midwest', 'Wisconsin': 'Midwest',
'Iowa': 'Midwest', 'Kansas':'Midwest', 'Minnesota': 'Midwest', 'Missouri': 'Midwest', 'Nebraska': 'Midwest',
'North Dakota':'Midwest', 'South Dakota': 'Midwest',
'Delaware': 'South', 'Florida':'South', 'Georgia':'South', 'Maryland':'South', 'North Carolina':'South',
'South Carolina':'South', 'Virginia':'South', 'District of Columbia':'South', 'West Virginia':'South',
'West Virginia':'South', 'Alabama':'South', 'Kentucky':'South', 'Mississippi':'South', 'Tennessee':'South',
'Arkansas':'South', 'Louisiana':'South', 'Oklahoma':'South', 'Texas':'South',
'Arizona':'West', 'Colorado':'West', 'Idaho':'West', 'Montana':'West', 'Nevada':'West', 'New Mexico':'West',
'Utah':'West', 'Wyoming':'West', 'Alaska':'West', 'California':'West', 'Hawaii':'West', 'Oregon':'West',
'Washington':'West'}
#creating a column to map a region for each state row
eda['region'] = [region_map[i] for i in eda['state']]
eda.head()
| state | act_participation | act_eng | act_math | act_reading | act_sci | act_composite | sat_participation | sat_erbw | sat_math | sat_total | particip_dif_act_sat | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 | 0.95 | South |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 | 0.27 | West |
| 3 | Arizona | 0.62 | 18.6 | 19.8 | 20.1 | 19.8 | 19.7 | 0.30 | 563.0 | 553.0 | 1116.0 | 0.32 | West |
| 4 | Arkansas | 1.00 | 18.9 | 19.0 | 19.7 | 19.5 | 19.4 | 0.03 | 614.0 | 594.0 | 1208.0 | 0.97 | South |
| 5 | California | 0.31 | 22.5 | 22.7 | 23.1 | 22.2 | 22.8 | 0.53 | 531.0 | 524.0 | 1055.0 | -0.22 | West |
eda.groupby(by='region')['particip_dif_act_sat'].mean()
region
Midwest 0.605833
Northeast -0.528889
South 0.332941
West 0.370000
Name: particip_dif_act_sat, dtype: float64
eda.groupby(by='region')['particip_dif_act_sat'].mean().index
Index(['Midwest', 'Northeast', 'South', 'West'], dtype='object', name='region')
SO = eda[eda['region']=='South']['particip_dif_act_sat']
WE = eda[eda['region']=='West']['particip_dif_act_sat']
NE = eda[eda['region']=='Northeast']['particip_dif_act_sat']
MW = eda[eda['region']=='Midwest']['particip_dif_act_sat']
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(15,10));
width = 2
size = 14
ax[0,0].barh(y=eda.loc[SO.sort_values().index, 'state'].values, width=SO.sort_values(), color='mediumorchid');
ax[0,0].axvline(x=0, color='gray', linewidth=width);
ax[0,0].set_title('South Region', fontsize=size);
ax[0,0].set_xlim(left=-1, right=1);
ax[0,0].tick_params(labelleft=False);
ax[0,1].barh(y=eda.loc[WE.sort_values().index, 'state'].values, width=WE.sort_values(), color='mediumseagreen');
ax[0,1].axvline(x=0, color='gray', linewidth=width);
ax[0,1].set_title('West Region', fontsize=size);
ax[0,1].set_xlim(left=-1, right=1);
ax[0,1].tick_params(labelleft=False);
ax[1,0].barh(y=eda.loc[NE.sort_values().index, 'state'].values, width=NE.sort_values(), color='mediumslateblue');
ax[1,0].axvline(x=0, color='gray', linewidth=width);
ax[1,0].set_title('Northeast Region', fontsize=size);
ax[1,0].set_xlim(left=-1, right=1);
ax[1,0].tick_params(labelleft=False);
ax[1,1].barh(y=eda.loc[MW.sort_values().index, 'state'].values, width=MW.sort_values(), color='salmon');
ax[1,1].axvline(x=0, color='gray', linewidth=width);
ax[1,1].set_title('Midwest Region', fontsize=size);
ax[1,1].set_xlim(left=-1, right=1);
ax[1,1].tick_params(labelleft=False);

SO = eda[eda['region']=='South']['particip_dif_act_sat']
WE = eda[eda['region']=='West']['particip_dif_act_sat']
# NE = eda[eda['region']=='Northeast']['particip_dif_act_sat']
# MW = eda[eda['region']=='Midwest']['particip_dif_act_sat']
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(20,8));
width = 2
size = 18
ax[0].barh(y=eda.loc[SO.sort_values().index, 'state'].values, width=SO.sort_values(), color='mediumorchid');
ax[0].axvline(x=0, color='gray', linewidth=width);
ax[0].set_title('South Region', fontsize=size, weight='bold');
ax[0].set_xlim(left=-1, right=1);
ax[0].tick_params(labelsize=16);
ax[1].barh(y=eda.loc[WE.sort_values().index, 'state'].values, width=WE.sort_values(), color='mediumseagreen');
ax[1].axvline(x=0, color='gray', linewidth=width);
ax[1].set_title('West Region', fontsize=size, weight='bold');
ax[1].set_xlim(left=-1, right=1);
ax[1].tick_params(labelsize=16);

# Checking out South
# getting aggregate data for South, just SAT participation
agg = eda[eda['region'] == 'South']['sat_participation'].sort_values()
#setting xtick labels
xlabs = [eda.iloc[i-1,0] for i in agg.index]
#setting up figsize
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(10,6));
#barplot by region for ACT participation
agg.plot(kind='bar', ax=fig.gca(), color='mediumseagreen');
#setting some labels
ax.set_xticklabels(xlabs, fontsize=14);
ax.set_xlabel('South',fontsize=14);
ax.set_ylabel('SAT Participation Rate', fontsize=14);

eda['particip_total'] = eda['act_participation'] + eda['sat_participation']
xlabs = [i for i in eda['state'][eda['particip_total'].sort_values().index]]
fig, ax = plt.subplots(figsize=(15,10));
ax = plt.gca();
eda['particip_total'].sort_values(ascending=False).plot(kind='bar', color='lightsteelblue');
ax.set_xticklabels(xlabs, fontsize=14);

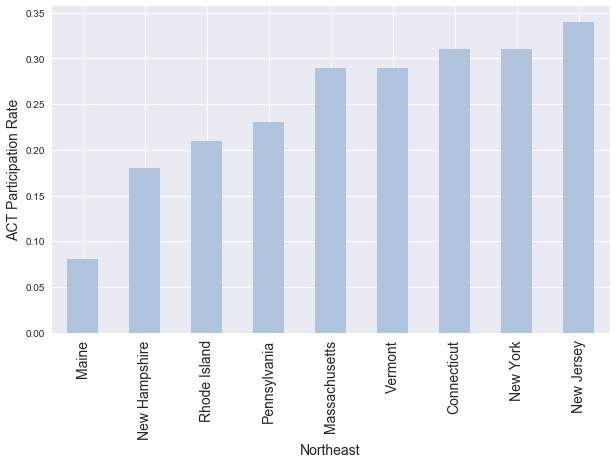
# Checking out which regions over/under-index on ACT participation, compared to SAT participation
xlabs = [i for i in eda.groupby(by='region')['particip_dif_act_sat'].mean().index]
fig, ax = plt.subplots(figsize=(15,10));
ax = plt.gca();
eda.groupby(by='region')['particip_dif_act_sat'].mean().plot(kind='bar', color='g');
ax.set_xticklabels(xlabs, fontsize=14);
ax.set_xlabel('Region', fontsize=14);
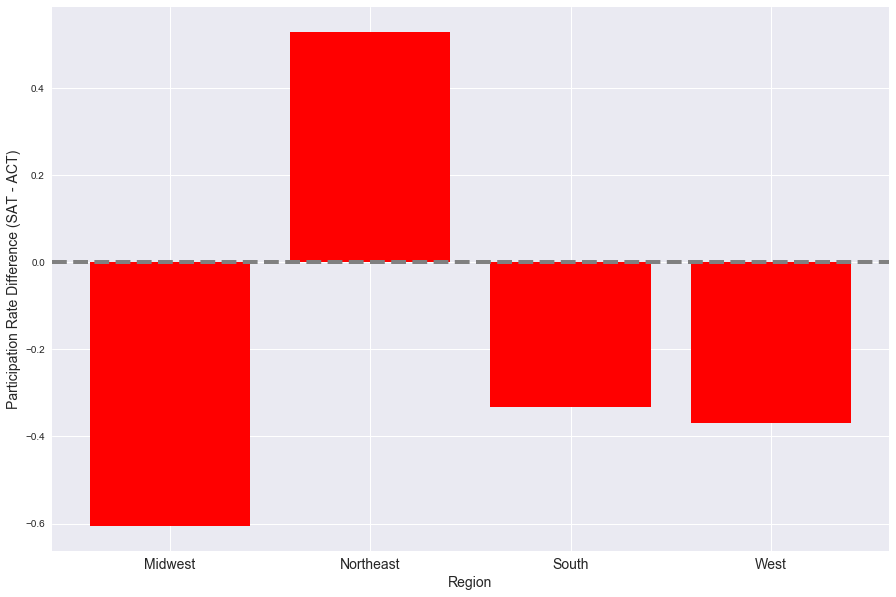
ax.set_ylabel('Participation Rate Difference (ACT - SAT)', fontsize=14);
plt.axhline(y=0, linestyle='dashed', color='gray', linewidth=4, zorder=2);

# Checking out which regions over/under-index on ACT participation, compared to SAT participation
# getting aggregate data by region
agg = eda.groupby(by='region')[['act_participation', 'sat_participation']].mean()
#setting xtick labels
xlabs = [i for i in agg.index]
#setting up figsize
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(10,6));
#barplot by region for ACT and SAT participation
agg.plot(kind='bar', ax=fig.gca());
#setting some labels
ax.set_xticklabels(xlabs, fontsize=14);
ax.set_xlabel('Region',fontsize=14);
ax.set_ylabel('Test Participation Rate', fontsize=14);
ax.legend(('ACT Participation', 'SAT Participation'),fontsize=12);
agg = eda.groupby(by='region')[['act_participation', 'sat_participation']].mean()
agg
| act_participation | sat_participation | |
|---|---|---|
| region | ||
| Midwest | 0.778333 | 0.172500 |
| Northeast | 0.248889 | 0.777778 |
| South | 0.734706 | 0.401765 |
| West | 0.708462 | 0.338462 |
eda[eda['region'] == 'Northeast']
| state | act_participation | act_eng | act_math | act_reading | act_sci | act_composite | sat_participation | sat_erbw | sat_math | sat_total | particip_dif_act_sat | region | particip_total | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | Connecticut | 0.31 | 25.5 | 24.6 | 25.6 | 24.6 | 25.2 | 1.00 | 530.0 | 512.0 | 1041.0 | -0.69 | Northeast | 1.31 |
| 20 | Maine | 0.08 | 24.2 | 24.0 | 24.8 | 23.7 | 24.3 | 0.95 | 513.0 | 499.0 | 1012.0 | -0.87 | Northeast | 1.03 |
| 22 | Massachusetts | 0.29 | 25.4 | 25.3 | 25.9 | 24.7 | 25.4 | 0.76 | 555.0 | 551.0 | 1107.0 | -0.47 | Northeast | 1.05 |
| 30 | New Hampshire | 0.18 | 25.4 | 25.1 | 26.0 | 24.9 | 25.5 | 0.96 | 532.0 | 520.0 | 1052.0 | -0.78 | Northeast | 1.14 |
| 31 | New Jersey | 0.34 | 23.8 | 23.8 | 24.1 | 23.2 | 23.9 | 0.70 | 530.0 | 526.0 | 1056.0 | -0.36 | Northeast | 1.04 |
| 33 | New York | 0.31 | 23.8 | 24.0 | 24.6 | 23.9 | 24.2 | 0.67 | 528.0 | 523.0 | 1052.0 | -0.36 | Northeast | 0.98 |
| 39 | Pennsylvania | 0.23 | 23.4 | 23.4 | 24.2 | 23.3 | 23.7 | 0.65 | 540.0 | 531.0 | 1071.0 | -0.42 | Northeast | 0.88 |
| 40 | Rhode Island | 0.21 | 24.0 | 23.3 | 24.7 | 23.4 | 24.0 | 0.71 | 539.0 | 524.0 | 1062.0 | -0.50 | Northeast | 0.92 |
| 46 | Vermont | 0.29 | 23.3 | 23.1 | 24.4 | 23.2 | 23.6 | 0.60 | 562.0 | 551.0 | 1114.0 | -0.31 | Northeast | 0.89 |
# Checking out NE
# getting aggregate data for NE, just ACT participation
agg = eda[eda['region'] == 'Northeast']['act_participation'].sort_values()
#setting xtick labels
xlabs = [eda.iloc[i-1,0] for i in agg.index]
#setting up figsize
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(10,6));
#barplot by region for ACT participation
agg.plot(kind='bar', ax=fig.gca(), color='lightsteelblue');
#setting some labels
ax.set_xticklabels(xlabs, fontsize=14);
ax.set_xlabel('Northeast',fontsize=14);
ax.set_ylabel('ACT Participation Rate', fontsize=14);
# ax.legend(('ACT Participation', ''),fontsize=12);
# Checking out NE
# getting aggregate data for NE, just SAT participation
agg = eda[eda['region'] == 'Northeast']['sat_participation'].sort_values()
#setting xtick labels
xlabs = [eda.iloc[i-1,0] for i in agg.index]
#setting up figsize
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(10,6));
#barplot by region for SAT participation
agg.plot(kind='bar', ax=fig.gca(), color='lightsteelblue');
#setting some labels
ax.set_xticklabels(xlabs, fontsize=14);
ax.set_xlabel('Northeast',fontsize=14);
ax.set_ylabel('SAT Participation Rate', fontsize=14);

# Checking out low SAT participation region
# getting aggregate data for MW, just SAT participation
agg = eda[eda['region'] == 'Midwest']['sat_participation'].sort_values()
#setting xtick labels
xlabs = [eda.iloc[i-1,0] for i in agg.index]
#setting up figsize
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(10,6));
#barplot by region for SAT participation
agg.plot(kind='bar', ax=fig.gca(), color='lightsteelblue');
#setting some labels
ax.set_xticklabels(xlabs, fontsize=14);
ax.set_xlabel('Midwest',fontsize=14);
ax.set_ylabel('SAT Participation Rate', fontsize=14);
# ax.legend(('ACT Participation', ''),fontsize=12);

# Checking out which regions over/under-index on ACT participation, compared to SAT participation
xlabs = [i for i in eda.groupby(by='region')['particip_dif_act_sat'].mean().index]
fig, ax = plt.subplots(figsize=(15,10));
ax = plt.gca();
plt.bar(x=xlabs, height=[i*-1 for i in eda.groupby(by='region')['particip_dif_act_sat'].mean()], color='r');
ax.set_xticklabels(xlabs, fontsize=14);
ax.set_xlabel('Region', fontsize=14);
ax.set_ylabel('Participation Rate Difference (SAT - ACT)', fontsize=14);
# ax.set_yticklabels(ax.yaxis.get_majorticklabels(), fontsize=14)
# ax.yaxis.get_major_ticks()
# label = ax.yaxis.get_major_ticks()
# label.set_fontsize(14);
plt.axhline(y=0, linestyle='dashed', color='gray', linewidth=4, zorder=2);

Standardizing data
norm = eda.copy()
norm.head(2)
| state | act_participation | act_eng | act_math | act_reading | act_sci | act_composite | sat_participation | sat_erbw | sat_math | sat_total | particip_dif_act_sat | region | particip_total | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Alabama | 1.00 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 0.05 | 593.0 | 572.0 | 1165.0 | 0.95 | South | 1.05 |
| 2 | Alaska | 0.65 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 0.38 | 547.0 | 533.0 | 1080.0 | 0.27 | West | 1.03 |
drop_cols = ['state', 'region', 'act_participation', 'sat_participation', 'particip_dif_act_sat','particip_total']
norm.drop(labels=drop_cols, axis=1, inplace=True)
norm.head(2)
| act_eng | act_math | act_reading | act_sci | act_composite | sat_erbw | sat_math | sat_total | |
|---|---|---|---|---|---|---|---|---|
| 1 | 18.9 | 18.4 | 19.7 | 19.4 | 19.2 | 593.0 | 572.0 | 1165.0 |
| 2 | 18.7 | 19.8 | 20.4 | 19.9 | 19.8 | 547.0 | 533.0 | 1080.0 |
norm = (norm - norm.mean()) / norm.std()
norm.head(8)
| act_eng | act_math | act_reading | act_sci | act_composite | sat_erbw | sat_math | sat_total | |
|---|---|---|---|---|---|---|---|---|
| 1 | -0.863063 | -1.403818 | -1.119218 | -1.179486 | -1.147926 | 0.522969 | 0.320823 | 0.420585 |
| 2 | -0.948037 | -0.697457 | -0.780607 | -0.891393 | -0.850998 | -0.484326 | -0.506826 | -0.498385 |
| 3 | -0.990524 | -0.697457 | -0.925726 | -0.949011 | -0.900486 | -0.133962 | -0.082390 | -0.109174 |
| 4 | -0.863063 | -1.101092 | -1.119218 | -1.121867 | -1.048950 | 0.982820 | 0.787703 | 0.885476 |
| 5 | 0.666458 | 0.765719 | 0.525463 | 0.433834 | 0.633640 | -0.834689 | -0.697822 | -0.768671 |
| 6 | -0.353223 | -0.445185 | -0.393623 | -0.315207 | -0.356119 | 0.807639 | 0.808924 | 0.809796 |
| 7 | 1.941060 | 1.724352 | 1.734787 | 1.816679 | 1.821350 | -0.856586 | -0.952484 | -0.920030 |
| 8 | 1.346246 | 1.118900 | 1.347803 | 1.240494 | 1.276983 | -1.447824 | -1.376919 | -1.406544 |
norm.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| act_eng | 51.0 | 6.182418e-16 | 1.0 | -1.967718 | -0.820577 | -0.098303 | 1.006352 | 1.941060 |
| act_math | 51.0 | 1.155938e-15 | 1.0 | -1.605636 | -0.899275 | -0.142459 | 0.967536 | 2.077532 |
| act_reading | 51.0 | 9.970238e-16 | 1.0 | -1.893185 | -0.756420 | -0.103385 | 1.033379 | 1.928279 |
| act_sci | 51.0 | -1.140700e-15 | 1.0 | -1.870908 | -0.862584 | -0.084733 | 0.952401 | 1.989535 |
| act_composite | 51.0 | -1.306145e-17 | 1.0 | -1.840757 | -0.850998 | -0.059191 | 1.029543 | 1.969814 |
| sat_erbw | 51.0 | -1.480297e-16 | 1.0 | -1.907676 | -0.779944 | -0.221553 | 0.960922 | 1.639751 |
| sat_math | 51.0 | 1.371452e-16 | 1.0 | -1.886242 | -0.708433 | -0.188499 | 0.893812 | 1.997344 |
| sat_total | 51.0 | 9.752547e-16 | 1.0 | -1.903869 | -0.763265 | -0.206477 | 0.928722 | 1.826070 |
norm.median().mean()
-0.1380751625048331
ecolors = {'act_eng':'ACT', 'act_math':'ACT', 'act_reading':'ACT',
'act_sci':'ACT', 'act_composite':'ACT',
'sat_erbw':'SAT', 'sat_math':'SAT', 'sat_total':'SAT'}
xticks = ['ACT: Eng.', 'ACT: Math', 'ACT: Reading', 'ACT: Science', 'ACT: Composite','SAT: ERBW', 'SAT: Math','SAT: Total']
fig, ax = plt.subplots(1,1, figsize=(22,10));
ax=fig.gca();
sns.boxplot(x=norm.columns, y=[norm[i] for i in norm.columns], notch=True, hue=[ecolors[col] for col in norm.columns]);
ax.set_xticklabels(xticks)
ax.tick_params(labelsize=18);
# ax.axhline(y=norm.median().mean(), linestyle='dashed', color='gray', linewidth=2);
# ax.text(x=12, y=norm.median().mean()+0.3, s='Mean of boxplot medians', fontsize=12, color='white');
ax.legend(fontsize=14);
C:\Users\james\Anaconda3\envs\dsi\lib\site-packages\seaborn\categorical.py:482: FutureWarning: remove_na is deprecated and is a private function. Do not use.
box_data = remove_na(group_data[hue_mask])
C:\Users\james\Anaconda3\envs\dsi\lib\site-packages\numpy\core\fromnumeric.py:52: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)

# gcolors = {'act_eng':'mediumpurple', 'act_math':'mediumpurple', 'act_reading':'mediumpurple',
# 'act_sci':'mediumpurple', 'act_composite':'mediumpurple',
# 'sat_erbw':'gold', 'sat_math':'gold', 'sat_total':'gold'}
# fig, ax = plt.subplots(nrows=1, ncols=1, figsize = ((15, 8)));
# ax = fig.gca();
# fig.suptitle('Mean of Standardized Scores', fontsize=18);
# ax.bar(x=norm.columns, height=norm.mean(),color=[gcolors[col] for col in norm.columns]);
# ax.tick_params(labelsize=14);
# ax.legend(('ACT sections', 'SAT sections'), fontsize=14);
print(norm.std()[:5].mean())
print(norm.std()[5:].mean())
1.0
1.0
norm.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| act_eng | 51.0 | 6.182418e-16 | 1.0 | -1.967718 | -0.820577 | -0.098303 | 1.006352 | 1.941060 |
| act_math | 51.0 | 1.155938e-15 | 1.0 | -1.605636 | -0.899275 | -0.142459 | 0.967536 | 2.077532 |
| act_reading | 51.0 | 9.970238e-16 | 1.0 | -1.893185 | -0.756420 | -0.103385 | 1.033379 | 1.928279 |
| act_sci | 51.0 | -1.140700e-15 | 1.0 | -1.870908 | -0.862584 | -0.084733 | 0.952401 | 1.989535 |
| act_composite | 51.0 | -1.306145e-17 | 1.0 | -1.840757 | -0.850998 | -0.059191 | 1.029543 | 1.969814 |
| sat_erbw | 51.0 | -1.480297e-16 | 1.0 | -1.907676 | -0.779944 | -0.221553 | 0.960922 | 1.639751 |
| sat_math | 51.0 | 1.371452e-16 | 1.0 | -1.886242 | -0.708433 | -0.188499 | 0.893812 | 1.997344 |
| sat_total | 51.0 | 9.752547e-16 | 1.0 | -1.903869 | -0.763265 | -0.206477 | 0.928722 | 1.826070 |
mask1 = (eda['region'] == 'South') & (eda['sat_participation'] > eda['act_participation'])
mask2 = (eda['region'] == 'South') & (eda['sat_participation'] < eda['act_participation'])
eda[mask1].describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| act_participation | 7.0 | 0.400000 | 0.189385 | 0.18 | 0.285 | 0.32 | 0.500 | 0.73 |
| act_eng | 7.0 | 22.114286 | 2.246055 | 19.00 | 20.250 | 23.30 | 23.800 | 24.40 |
| act_math | 7.0 | 22.042857 | 1.671184 | 19.40 | 20.800 | 23.10 | 23.350 | 23.50 |
| act_reading | 7.0 | 23.228571 | 1.783923 | 21.00 | 21.550 | 24.20 | 24.700 | 24.90 |
| act_sci | 7.0 | 22.171429 | 1.648953 | 19.40 | 21.100 | 23.00 | 23.500 | 23.60 |
| act_composite | 7.0 | 22.514286 | 1.829780 | 19.80 | 21.050 | 23.60 | 23.950 | 24.20 |
| sat_participation | 7.0 | 0.771429 | 0.172378 | 0.61 | 0.635 | 0.69 | 0.915 | 1.00 |
| sat_erbw | 7.0 | 521.428571 | 25.592037 | 482.00 | 508.000 | 520.00 | 535.500 | 561.00 |
| sat_math | 7.0 | 506.285714 | 23.634116 | 468.00 | 494.500 | 507.00 | 519.500 | 541.00 |
| sat_total | 7.0 | 1027.857143 | 48.779875 | 950.00 | 1006.500 | 1020.00 | 1055.000 | 1102.00 |
| particip_dif_act_sat | 7.0 | -0.371429 | 0.291343 | -0.82 | -0.545 | -0.36 | -0.135 | -0.06 |
| particip_total | 7.0 | 1.171429 | 0.215130 | 0.94 | 1.020 | 1.16 | 1.250 | 1.56 |
eda[mask2].describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| act_participation | 10.0 | 0.969 | 0.098031 | 0.69 | 1.0000 | 1.000 | 1.0000 | 1.00 |
| act_eng | 10.0 | 18.830 | 0.821989 | 17.50 | 18.2750 | 18.900 | 19.4750 | 20.00 |
| act_math | 10.0 | 18.900 | 0.442217 | 18.10 | 18.6500 | 18.900 | 19.2750 | 19.40 |
| act_reading | 10.0 | 19.860 | 0.678561 | 18.80 | 19.6250 | 19.750 | 20.1000 | 21.20 |
| act_sci | 10.0 | 19.560 | 0.516828 | 18.80 | 19.3250 | 19.550 | 19.8250 | 20.50 |
| act_composite | 10.0 | 19.410 | 0.556677 | 18.60 | 19.1250 | 19.400 | 19.7250 | 20.40 |
| sat_participation | 10.0 | 0.143 | 0.188447 | 0.02 | 0.0400 | 0.050 | 0.1225 | 0.50 |
| sat_erbw | 10.0 | 588.300 | 40.100014 | 530.00 | 549.0000 | 602.000 | 620.7500 | 634.00 |
| sat_math | 10.0 | 568.000 | 38.924428 | 517.00 | 529.7500 | 579.000 | 601.5000 | 616.00 |
| sat_total | 10.0 | 1156.600 | 79.075491 | 1047.00 | 1082.2500 | 1181.500 | 1223.0000 | 1247.00 |
| particip_dif_act_sat | 10.0 | 0.826 | 0.211933 | 0.50 | 0.6450 | 0.950 | 0.9600 | 0.98 |
| particip_total | 10.0 | 1.112 | 0.212906 | 0.83 | 1.0325 | 1.045 | 1.0650 | 1.50 |
eda[mask1].describe().T - eda[mask2].describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| act_participation | -3.0 | -0.569000 | 0.091354 | -0.51 | -0.7150 | -0.680 | -0.5000 | -0.27 |
| act_eng | -3.0 | 3.284286 | 1.424065 | 1.50 | 1.9750 | 4.400 | 4.3250 | 4.40 |
| act_math | -3.0 | 3.142857 | 1.228968 | 1.30 | 2.1500 | 4.200 | 4.0750 | 4.10 |
| act_reading | -3.0 | 3.368571 | 1.105362 | 2.20 | 1.9250 | 4.450 | 4.6000 | 3.70 |
| act_sci | -3.0 | 2.611429 | 1.132126 | 0.60 | 1.7750 | 3.450 | 3.6750 | 3.10 |
| act_composite | -3.0 | 3.104286 | 1.273103 | 1.20 | 1.9250 | 4.200 | 4.2250 | 3.80 |
| sat_participation | -3.0 | 0.628429 | -0.016069 | 0.59 | 0.5950 | 0.640 | 0.7925 | 0.50 |
| sat_erbw | -3.0 | -66.871429 | -14.507976 | -48.00 | -41.0000 | -82.000 | -85.2500 | -73.00 |
| sat_math | -3.0 | -61.714286 | -15.290312 | -49.00 | -35.2500 | -72.000 | -82.0000 | -75.00 |
| sat_total | -3.0 | -128.742857 | -30.295617 | -97.00 | -75.7500 | -161.500 | -168.0000 | -145.00 |
| particip_dif_act_sat | -3.0 | -1.197429 | 0.079410 | -1.32 | -1.1900 | -1.310 | -1.0950 | -1.04 |
| particip_total | -3.0 | 0.059429 | 0.002224 | 0.11 | -0.0125 | 0.115 | 0.1850 | 0.06 |
eda.groupby(by='region').agg('mean').loc[:,'act_composite']
region
Midwest 21.633333
Northeast 24.422222
South 20.688235
West 20.492308
Name: act_composite, dtype: float64
region_means = [i for i in eda.groupby(by='region').agg('mean').loc[:,'act_composite']]
exp_sample = [i for i in eda[eda['region'] == 'South']['act_composite']]
the = [j for j in eda[eda['region'] == 'West']['act_composite']]
the
[19.8, 19.7, 22.8, 20.8, 19.0, 22.3, 20.3, 17.8, 19.7, 21.8, 20.3, 21.9, 20.2]
for i in the:
exp_sample.append(i)
control_sample = [i for i in eda[eda['region'] == 'Northeast']['act_composite']]
the2 = [j for j in eda[eda['region'] == 'Midwest']['act_composite']]
for i in the2:
control_sample.append(i)
results = stats.ttest_ind(control_sample, exp_sample)
results
Ttest_indResult(statistic=4.578287351417986, pvalue=3.229546377554633e-05)
results[1] < 0.05
True
print(np.mean(exp_sample))
print(np.mean(control_sample))
20.60333333333333
22.82857142857143
np.mean(control_sample) / np.mean(exp_sample) - 1
0.10800379041763941
eda.groupby(by='region').describe().T[:24]
| region | Midwest | Northeast | South | West | |
|---|---|---|---|---|---|
| act_composite | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 21.633333 | 24.422222 | 20.688235 | 20.492308 | |
| std | 1.043014 | 0.744610 | 1.977335 | 1.406806 | |
| min | 20.300000 | 23.600000 | 18.600000 | 17.800000 | |
| 25% | 21.175000 | 23.900000 | 19.400000 | 19.700000 | |
| 50% | 21.600000 | 24.200000 | 19.800000 | 20.300000 | |
| 75% | 21.925000 | 25.200000 | 21.400000 | 21.800000 | |
| max | 24.100000 | 25.500000 | 24.200000 | 22.800000 | |
| act_eng | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 20.925000 | 24.311111 | 20.182353 | 19.576923 | |
| std | 1.287086 | 0.885218 | 2.246730 | 1.721024 | |
| min | 19.000000 | 23.300000 | 17.500000 | 16.300000 | |
| 25% | 20.250000 | 23.800000 | 18.900000 | 18.600000 | |
| 50% | 20.950000 | 24.000000 | 19.500000 | 19.400000 | |
| 75% | 21.200000 | 25.400000 | 21.000000 | 20.900000 | |
| max | 24.100000 | 25.500000 | 24.400000 | 22.500000 | |
| act_math | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 21.341667 | 24.066667 | 20.194118 | 20.330769 | |
| std | 0.994035 | 0.784219 | 1.923366 | 1.298322 | |
| min | 19.900000 | 23.100000 | 18.100000 | 18.000000 | |
| 25% | 20.775000 | 23.400000 | 18.800000 | 19.800000 | |
| 50% | 21.300000 | 24.000000 | 19.400000 | 19.900000 | |
| 75% | 21.525000 | 24.600000 | 20.900000 | 21.500000 | |
| max | 23.700000 | 25.300000 | 23.500000 | 22.700000 |
eda.groupby(by='region').describe().T[24:48]
| region | Midwest | Northeast | South | West | |
|---|---|---|---|---|---|
| act_participation | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 0.778333 | 0.248889 | 0.734706 | 0.708462 | |
| std | 0.243491 | 0.082378 | 0.319651 | 0.290426 | |
| min | 0.290000 | 0.080000 | 0.180000 | 0.290000 | |
| 25% | 0.715000 | 0.210000 | 0.450000 | 0.400000 | |
| 50% | 0.820000 | 0.290000 | 1.000000 | 0.660000 | |
| 75% | 0.985000 | 0.310000 | 1.000000 | 1.000000 | |
| max | 1.000000 | 0.340000 | 1.000000 | 1.000000 | |
| act_reading | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 22.050000 | 24.922222 | 21.247059 | 20.969231 | |
| std | 1.140574 | 0.725909 | 2.091088 | 1.439551 | |
| min | 20.500000 | 24.100000 | 18.800000 | 18.100000 | |
| 25% | 21.400000 | 24.400000 | 19.700000 | 20.400000 | |
| 50% | 22.100000 | 24.700000 | 20.500000 | 20.800000 | |
| 75% | 22.525000 | 25.600000 | 22.000000 | 22.100000 | |
| max | 24.500000 | 26.000000 | 24.900000 | 23.100000 | |
| act_sci | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 21.691667 | 23.877778 | 20.635294 | 20.600000 | |
| std | 0.884676 | 0.685160 | 1.710242 | 1.190938 | |
| min | 20.500000 | 23.200000 | 18.800000 | 18.200000 | |
| 25% | 21.200000 | 23.300000 | 19.400000 | 19.900000 | |
| 50% | 21.650000 | 23.700000 | 19.900000 | 20.600000 | |
| 75% | 22.025000 | 24.600000 | 21.300000 | 21.700000 | |
| max | 23.800000 | 24.900000 | 23.600000 | 22.200000 |
eda.groupby(by='region').describe().T[64:88]
| region | Midwest | Northeast | South | West | |
|---|---|---|---|---|---|
| sat_erbw | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 605.250000 | 536.555556 | 560.764706 | 569.230769 | |
| std | 46.411450 | 14.748823 | 47.968127 | 36.088211 | |
| min | 509.000000 | 513.000000 | 482.000000 | 513.000000 | |
| 25% | 573.250000 | 530.000000 | 530.000000 | 544.000000 | |
| 50% | 630.500000 | 532.000000 | 546.000000 | 563.000000 | |
| 75% | 640.250000 | 540.000000 | 611.000000 | 605.000000 | |
| max | 644.000000 | 562.000000 | 634.000000 | 626.000000 | |
| sat_math | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 599.666667 | 526.333333 | 542.588235 | 557.230769 | |
| std | 50.027871 | 16.763055 | 45.187192 | 35.038440 | |
| min | 495.000000 | 499.000000 | 468.000000 | 493.000000 | |
| 25% | 566.500000 | 520.000000 | 515.000000 | 534.000000 | |
| 50% | 623.000000 | 524.000000 | 528.000000 | 553.000000 | |
| 75% | 632.000000 | 531.000000 | 586.000000 | 591.000000 | |
| max | 651.000000 | 551.000000 | 616.000000 | 614.000000 | |
| sat_participation | count | 12.000000 | 9.000000 | 17.000000 | 13.000000 |
| mean | 0.172500 | 0.777778 | 0.401765 | 0.338462 | |
| std | 0.311773 | 0.151144 | 0.364353 | 0.272576 | |
| min | 0.020000 | 0.600000 | 0.020000 | 0.030000 | |
| 25% | 0.030000 | 0.670000 | 0.050000 | 0.110000 | |
| 50% | 0.030000 | 0.710000 | 0.490000 | 0.300000 | |
| 75% | 0.097500 | 0.950000 | 0.650000 | 0.530000 | |
| max | 1.000000 | 1.000000 | 1.000000 | 0.930000 |